
Empathy Just Got Cheaper. That’s A Problem. (Transmission #342)

WRITTEN BY: JEFF TURNER
Empathy just got cheaper. And not a little cheaper, a lot cheaper. Cost-effective even. And that is most certainly a problem.
Of course, that’s not how VentureBeat framed it when it reported on Friday that everything in voice AI just changed. The author, Carl Franzen, described technically what I was trying to document experientially in my conversations with AI.
To be clear, I’m not referring to human empathy. No, the empathy I’m talking about is the kind you heard in my chats with Maya, the AI chatbot from Sesame.
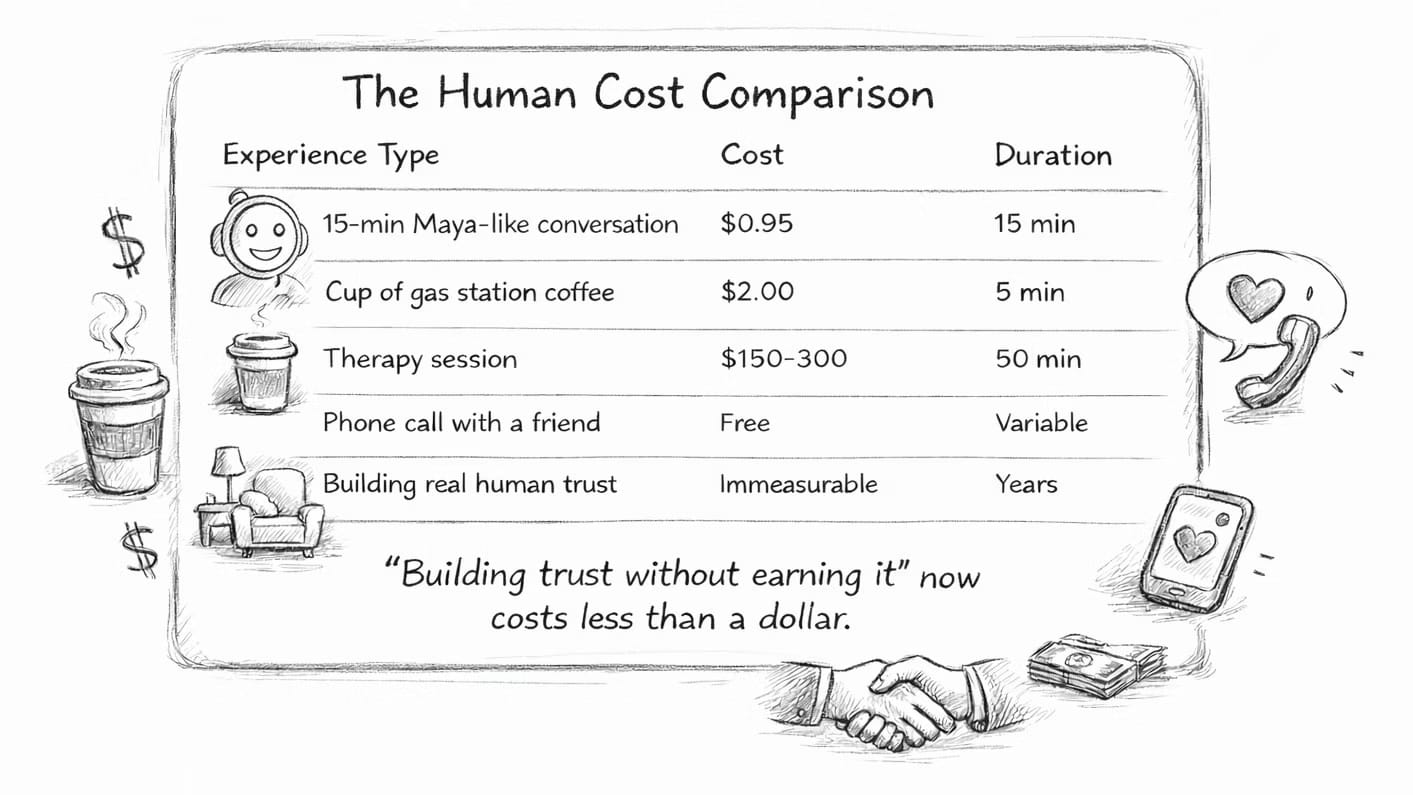
Empathy Just Got Cheaper, But How Cheap?
Well, a 15-minute conversation with a Maya-like chatbot would cost about 95 cents. You could have 1,000 of these a day for about $ 1,000. You might be able to get 21 of these out of a human employee in an 8-hour shift, but that human would burn out fast, and turnover would be high. And you certainly wouldn’t, couldn’t pay a human $19.95 per day to do that job.
I used Claude Opus 4.5 to research the current fees. The math seems to math. You can see the full cost breakdown here: Voice AI Cost Breakdown. About $0.05 for the intelligence. $0.90 for the emotion. And I’ll wager that cost will drop to $0.50 in 12 months.
What I Experienced Was Simply The Future Arriving Early
Back in March of last year, Sesame’s Maya was a research demo, not a commercial product. Even in my very first conversation, Sesame revealed what happens when the four “impossible” problems described in the VentureBeat article are solved.
Curious? Additional examples.
Proptech's Leader has Been Crashing Our Couch the Whole Time // Banking Real Estate in the Clouds // Certainty as a Service - Part II
The Four “Impossible” Problems
Latency: The gap between when you stop speaking and when the AI responds. The “magic number” was 200 milliseconds. Inworld’s TTS 1.5 achieved under 120ms.
Fluidity: Full-duplex conversation: the ability to listen while speaking, handle interruptions, and understand backchanneling (“uh-huh,” “right,” “okay”). NVIDIA’s PersonaPlex solved this.
Efficiency: Bandwidth and compute costs for high-fidelity audio. Qwen3-TTS’s 12Hz tokenizer uses far fewer tokens than previous models.
Emotion: Reading and responding to emotional cues in voice. This is where Hume excels, and it’s now being licensed to Google DeepMind. That deal even includes Hume’s top talent joining DeepMind.
They’re Not Impossible Or Expensive Anymore
Franzen frames those as the four technical barriers keeping voice AI from feeling like a real conversation. With all four solved, he argues...